Från DIGG community / community
@elenorweijmar spännande fråga som jag ser fram emot att följa och håller med Nina att detta måste diskuteras...
Hör gärna av er så kan jag visa hur en kunskapsgraf som Wikidata fungerar och olika aktiviteter vi gör för att öka datakvaliten. I veckan pratade jag på 2021 LD4 Conference on Linked Data och nämnde kort ett nytt verktyg från Wikidata video / Wikidata:Mismatch_Finder för att förbättra datakvaliten -
this tool will help to make it easier for editors to find and fix the mismatches between Wikidata’s data and other databases.
Tyvärr ser jag inte att DIGG aktivt drivit på detta med kvalitet utan som jag uppfattar sitter stilla i båten och hoppas det blir bra... lesson learned är att det blir det inte av sig själv.... rätta mig om jag har fel.
Det vi ser från "utsidan" är att DIGG inte klarar av att logga sina egna helpdesk problem och ge oss ett spårbart id se det galna problemet med sortera senast upplagda dataset så det visas först) - borde inte vara svårare än att ha en databas stored procedure som sätter en tidsstämpel och sedan sortera på det....
Datakvalite är A och O
Det finns enormt många saker som måste upp på bordet för att Öppna data skall bli användbart
skapa en svensk kunskapsgraf se försök till dialog där DIGG lovade att jobba med sökningen men verkar inte se att vägen framåt är en kunskapsgraf, länkade data utan någon egen variant av exclude och om man har samma spec det sistnämda är ett litet steg åt rätt håll.... brist på att DIGG har en publik prioriterad backlog gör att vi inte vet vad som händer....
löftet är att vi skall bli bäst i världen enligt nedanstående citat men jag tycker mig inte se att det finns en plan och att det finns pondus att skapa detta.... finns säkert massa ursäkter men så svårt borde det inte vara 2021 att få något att hända....

det verkar drivas projekt men det är mer old school utan publika backlogs eller dialog se den oro jag kände efter att ha lyssnat på Öppna data-utredningen där jag uppfattar att ordet datadriven arbetsmarknad missförstods av en person i projektet....
Vi har samma problem med den Europeiska Dataportalen (EDP) senast jag kollade... se Jupyter Notebook det galna i denna sörja är att DIGG brukar referera till EDP där dom utrycker mognaden hos Sverige... jag ställde frågan till EDP hur dom mäter kvalite på Sverige dataportal och då var svaret att man räknar antal uppladdade dataset och inget mer.... känns som att räkna antal tandpetare på en restaurang och dra slutsatsen om det är en bra restaurang eller inte....

Hur svårt kan det vara?
Jag gjorde 2 tester om man kan jobba på annorlunda sätt med ett verktyg som Wikidata
- Badvatten se github.com Svenskabadplatser där jag skapade en enkel spec i ShEx EntitySchema:E305 laddade upp det jag hitta hos Havsmyndigheten, kontaktade Europieska EEA om även övriga Europa var en fri icenbs CC-0 (svar nja), hade en kort dialog med Havsmyndigheten som inte var intresserad (min uppfattning oldschool myndighet som inte jobbar agilt och har tydliga produktägare)
1-1) exempel hur vi följer upp datakvaliten för 2896 badplatser
1-2) exempel hur GITHUB issues används till att spåra fel
1-3) Wikidata i sig är en Wiki så det finns stöd för versionshantering, prenumerera, kommentera, rulla tillbaka versioner etc. och alla kan kommentera/ ändra fel på gott och ont....
- Utegym det visade sig att badvatten har en koppling till EEA via bathingwateridentifier Wikidata Property:P9616 vilket gjorde det lite komplext så då testade jag att samla in alla utegym i Sverige dvs. enormt enkelt data typ namn, koordinat, websida enklarare dataset finns inte och det känns kriminellt om detta data inte är fritt var utegymen finns
")
2.1 projekt Wikidata:WikiProject_Outdoor_Gyms
2.2 kommunikation med kommunerna har jag som Issues i GITHUB
2.2.1 om jag tror kommunen klarar av Öppna data markerar jag det
2.3 ett enkelt schema skapades EntitySchema:E280
2.4 allt data ligger i Wikidata --> vi enkelt kan skapa en coverage över vilket data vi har för ex. svenska kommuner > 250 stycken eller per land
Lyssna gärna på de inspelade föredragen från LD4 där har nu institutioner som presenterade mest amerikanska aktörer som Stanford University Libraries, USA:s kongressbibliotek , Columbia University, Harvard Library .... börjat inse att länkade data är vägen framåt MEN dom inser även att det finns inga enkla lösningar utan det krävs styrning och ledarskap.... min vaga förhoppning var att DIGG skulle få det ansvaret och även ta det men idag känns hela detta med Öppna data i Sverige lite trött... jag har med en dåres envishet tjatat att det behövs nya laguppställningar för att lyckas...
Jag skrev ned lite ostruktiurerat vad jag ser behövs för en organisation för att koppla ihop sig med Wikidata och det fel jag hittat (jag har gjort > 1 million redigeringar)
- One way to design a system to be a good external identifier in Wikidata
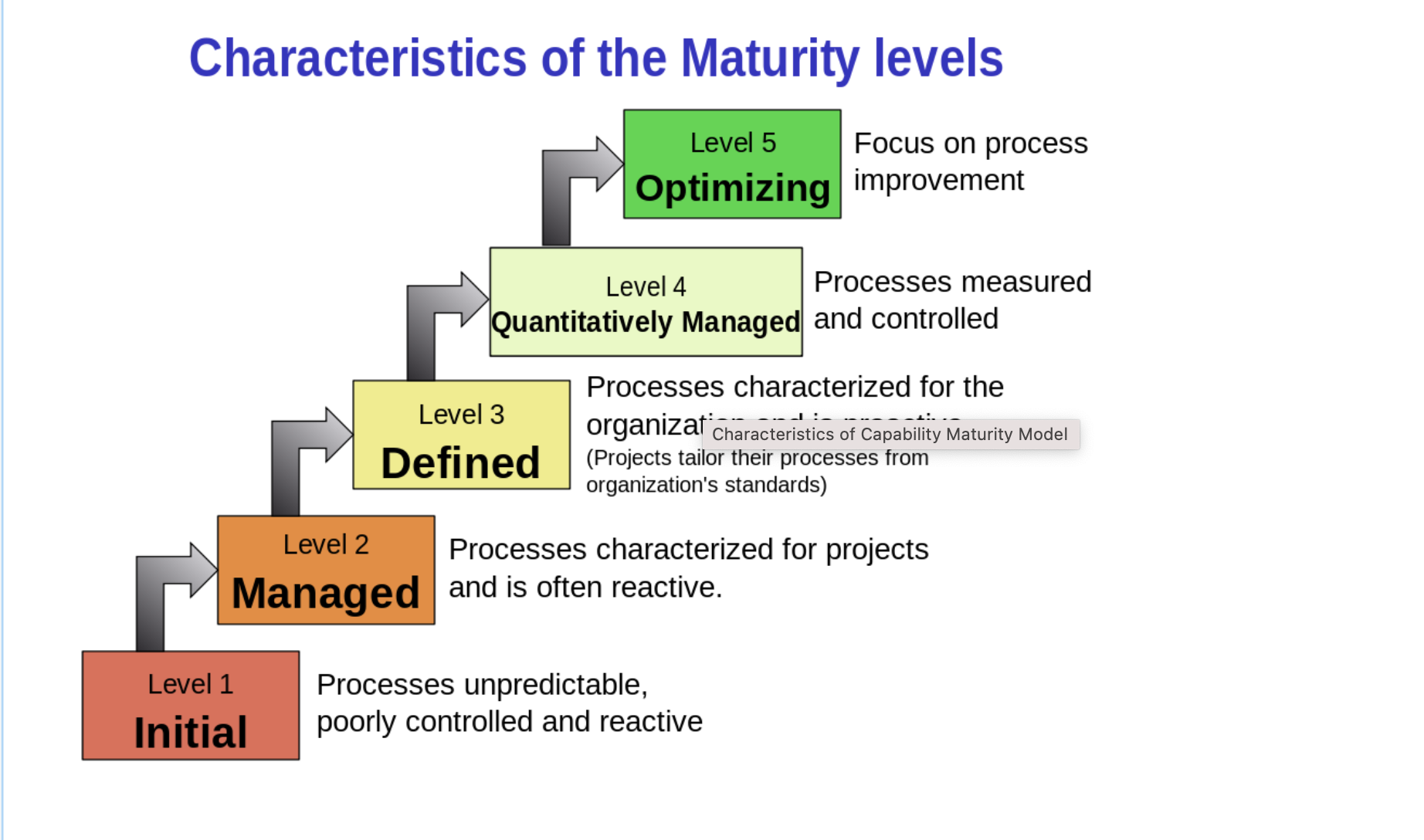
där jag på slutet har med nedanstående modell som borde kunna överföras till hur vi hanterar datakvalitet... jag brukar även ofta prata om metadatadebt dvs,. den kostnad vi ser av att ha dålig metadata (ex. strings not things)
Men som sagt hör gärna av er och som LD4 trycker på så skall detta fungera så måste vi skapa en dialog - Building Connections together

Magnus Sälgö
+46-735152802
Inga kommentarer:
Skicka en kommentar